What's Foley?
Abstract
Video-to-audio (V2A) generation aims to synthesize realistic audio that is both semantically consistent with and temporally synchronized to a silent video. Despite recent progress, many methods still rely on multi-stage training, resulting in high computational costs and long runtimes, or transform visual input into text to leverage pretrained text-to-audio models, sacrificing fine-grained temporal cues. To overcome these limitations, we propose Flowley, an end-to-end, single-stage training architecture that produces soundtracks by combining visual features with textual prompts. Crucially, we introduce Progressive Soft-masked Cross-Attention, which embeds audio-visual synchronization directly within its attention mechanism, adding zero additional computational cost compared to standard attention layers. We further observe that existing V2A benchmarks lack sound-oriented descriptive captions, which can potentially degrade the quality of the synthesized audio. To remedy this, we propose SoundCap, a plug-and-play pipeline for creating detailed, sound-aware captions that guide the model. Remarkably, without integrating any pretrained audio-visual alignment modules, Flowley achieves state-of-the-art performance on VGGSound across multiple metrics. Moreover, by incorporating SoundCap, we further exceed the performance of the strongest existing close-sourced methods in terms of audio quality in the zero-shot setting.
Flowley Architecture
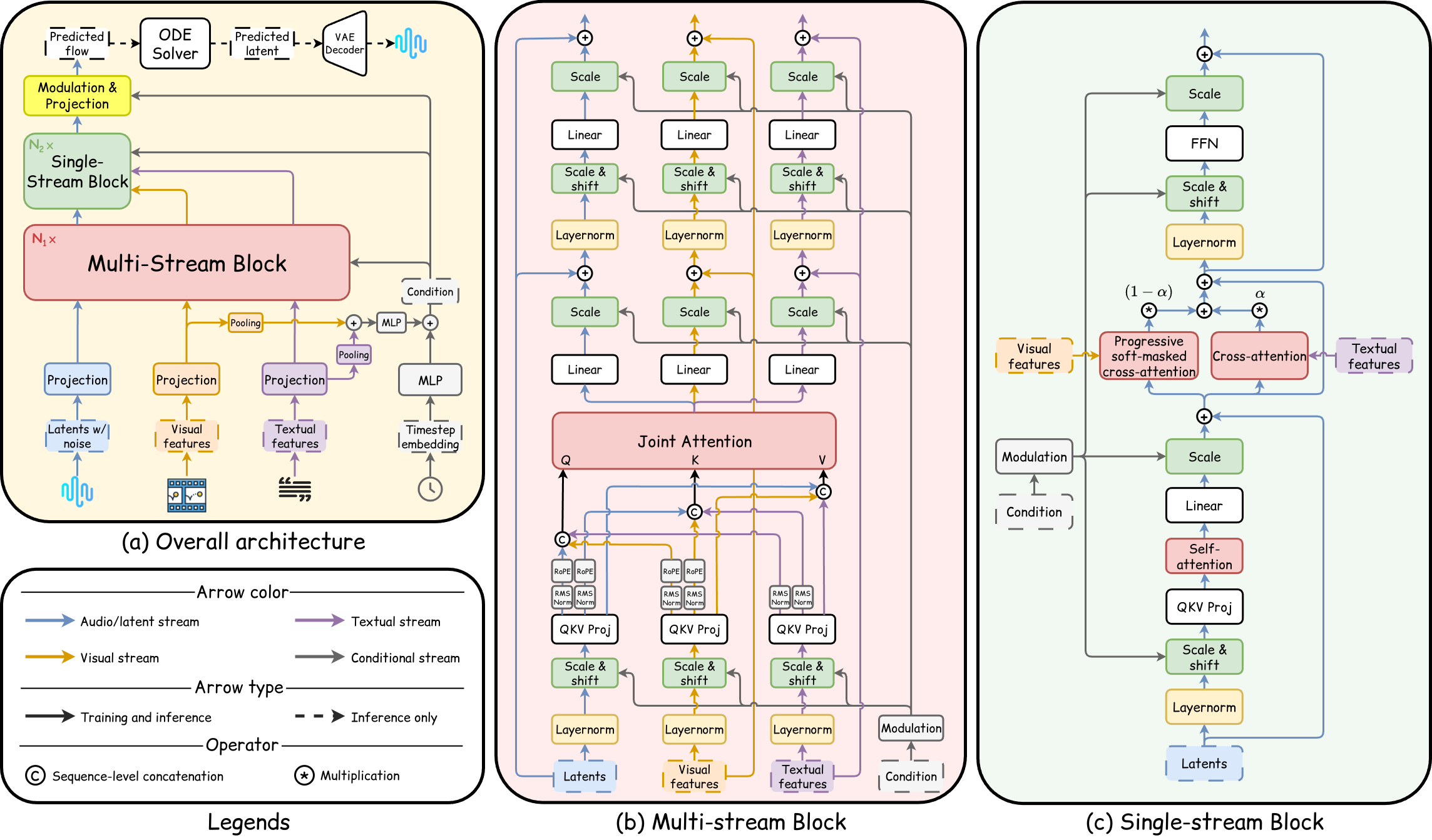
Figure 1: (a) The proposed Flowley framework consists of two core modules. (b) First, visual, textual, and audio latent representations are processed together through the multi-stream block. (c) Latent features are then passed into the single-stream block, where they undergo weighted cross-attention with the visual and textual streams to estimate the flow field. At inference time, we integrate this learned flow using standard ODE solvers to generate the compressed mel-spectrogram, which is subsequently decoded and vocoded into the final audio waveform.